到目前為止,我們的 Notebook 裡有很多零散的程式碼:
缺點是:
👉 今天我們要做的事:
建立一個乾淨的 Pipeline 模組,包含:
load_data() → 載入資料train_model() → 訓練模型evaluate_and_log() → 評估並記錄到 MLflow提供一個 run_pipeline.py,一鍵就能跑完整流程。
請在專案裡新增以下檔案與資料夾:
/usr/mlflow/src/pipeline/
└── pipeline.py # 定義 Pipeline 類別
/usr/mlflow/run_pipeline.py # 主程式,呼叫 pipeline 執行
這是我們的核心模組。
📂 路徑:/usr/mlflow/src/pipeline/pipeline.py
import os
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import mlflow
DATA_DIR = "/usr/mlflow/data"
class AnimePipeline:
def __init__(self, sample_size=1000):
self.sample_size = sample_size
def load_data(self):
"""載入動畫資料,只取部分樣本確保 3 分鐘內可跑完"""
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
# 取樣,避免全量跑太久
anime = anime.sample(self.sample_size, random_state=42).reset_index(drop=True)
return anime, ratings_train
def train_model(self, anime, max_features=1000, ngram_range=(1,1), min_df=2):
"""用 TF-IDF 訓練 item-based 模型"""
vectorizer = TfidfVectorizer(
stop_words="english",
max_features=max_features,
ngram_range=ngram_range,
min_df=min_df
)
tfidf = vectorizer.fit_transform(anime["genre"].fillna(""))
sim_matrix = cosine_similarity(tfidf)
return sim_matrix
def evaluate_and_log(self, anime, sim_matrix, params):
"""簡單評估 Precision@10 並 log 到 MLflow"""
def precision_at_k(recommended, relevant, k=10):
return len(set(recommended[:k]) & set(relevant)) / k
# 隨機測 30 部動畫,控制時間
test_idx = np.random.choice(len(anime), 30, replace=False)
scores = []
for idx in test_idx:
sim_scores = list(enumerate(sim_matrix[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
top_idx = [i for i, _ in sim_scores[1:11]]
recommended = anime.iloc[top_idx]["name"].tolist()
relevant = anime[anime["genre"] == anime.iloc[idx]["genre"]]["name"].tolist()
if len(relevant) > 1:
scores.append(precision_at_k(recommended, relevant, k=10))
avg_precision = np.mean(scores)
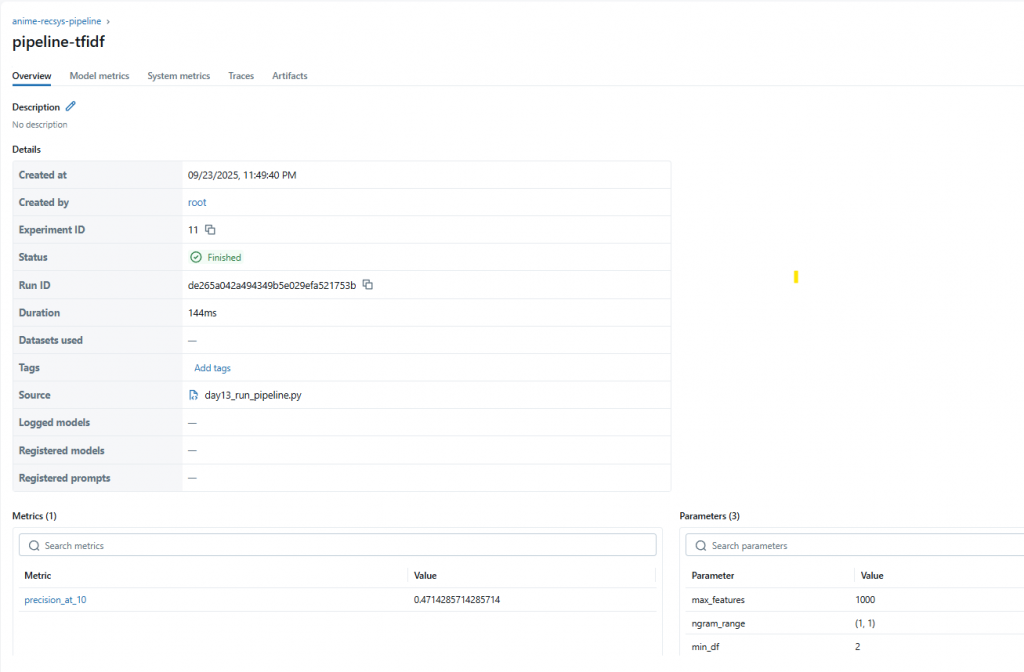
with mlflow.start_run(run_name="pipeline-tfidf") as run:
mlflow.log_params(params) # 紀錄參數
mlflow.log_metric("precision_at_10", avg_precision) # 紀錄指標
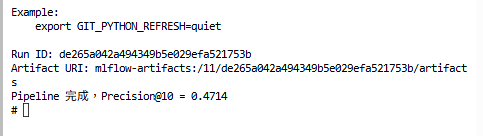
print("Run ID:", run.info.run_id)
print("Artifact URI:", run.info.artifact_uri)
return avg_precision
這是 pipeline 的執行入口。
📂 路徑:/usr/mlflow/day13_run_pipeline.py
import mlflow
from src.pipeline.pipeline import AnimePipeline
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-pipeline")
def main():
pipeline = AnimePipeline(sample_size=1000) # 控制資料量
anime, ratings_train = pipeline.load_data()
params = {
"max_features": 1000,
"ngram_range": (1,1),
"min_df": 2
}
sim_matrix = pipeline.train_model(anime, **params)
score = pipeline.evaluate_and_log(anime, sim_matrix, params)
print(f"Pipeline 完成,Precision@10 = {score:.4f}")
if __name__ == "__main__":
main()
在 python-dev 容器內執行:
python day13_run_pipeline.py
執行後,你會看到:
run_pipeline.py
│
▼
AnimePipeline
├── load_data() → 抽樣資料
├── train_model() → TF-IDF 訓練
└── evaluate_and_log() → Precision@10 → MLflow
run_pipeline.py,可以一鍵跑完流程。

 iThome鐵人賽
iThome鐵人賽